Un patrón de diseño no es una solucion final absoluta que puede transformarse directamente a código, es una descripción o plantilla de como resolver un problema que puede usarse en muchas situaciones diferentes.
Los patrones de diseño pueden acelerar el proceso de desarrollo, al proporcionar paradigmas que muchas veces han sido probados útiles.
Estos patrones de diseño tratan acerca de la instanciación de clase. Esta clase puede dividirse en patrones de creación de clases y patrones de creación de objetos. Los patrones de creación de clases usan herencia en el proceso de instanciación y los patrones de creación de objetos usan la delegación para realizar el trabajo.
Patrones de creación
Estos patrones de diseño tratan acerca de la instanciación de clase. Esta clase puede dividirse en patrones de creación de clases y patrones de creación de objetos. Los patrones de creación de clases usan herencia en el proceso de instanciación y los patrones de creación de objetos usan la delegación para realizar el trabajo.
- Abstract Factory
Provee una interfaz para crear familias de objetos relacionados o dependientes, sin especificar sus clases concretas.

- Builder
Separa la construcción de un objeto complejo de su representación de tal manera que el mismo proceso de construcción pueda crear distintas representaciones.

- Factory Method
Define una interfaz para crear un objeto, pero deja que las subclases decidan que clase instanciar. Permite que una clase delegue la creación de objetos a sus subclases.

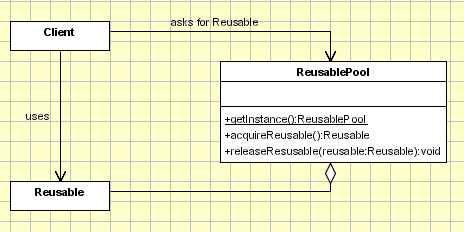
- Prototype


Patrones estructurales
Estos patrones de diseño tratan sobre la composicion de clases y objetos. Estos patrones usan herencia para componer interfaces. Definen maneras de componer un objeto para obtener nuevas funcionalidades.
- Adapter


- Composite

- Decorator
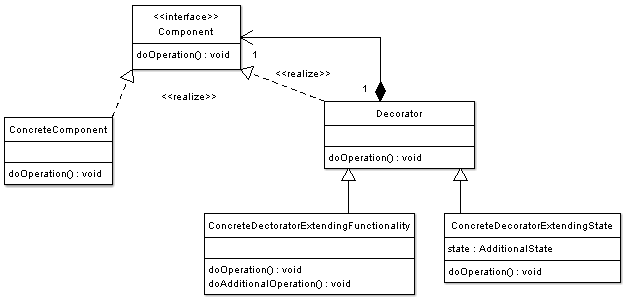
- Facade

- Flyweight

- Private Class Data

- Proxy

Patrones de comportamiento
Estos patrones tratan acerca de la comunicacion entre objetos y conjuntos de estos.
- Chain of responsibility
Evita emparejar el objeto que envía una petición con el objeto que recibe esa petición, al permitir que mas de un objeto pueda tomar la responsabilidad de la petición enviada. Encadena los objetos que podrán recibir la petición y pasa la petición a lo largo de la cadena hasta que un objeto acepte la petición.

- Command

- Interpreter

- Iterator
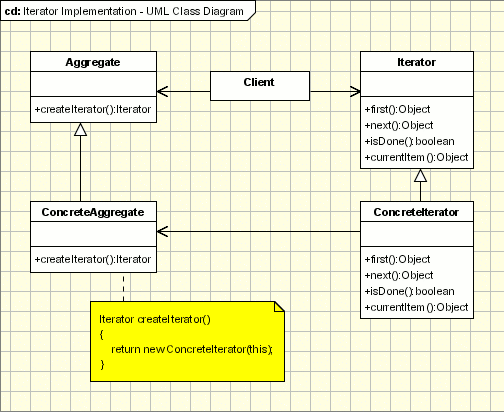
- Mediator
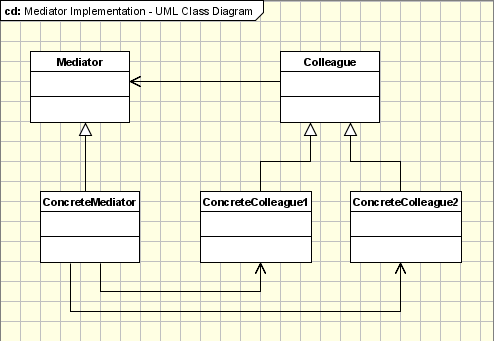
- Memento


- Observer

- State

- Strategy

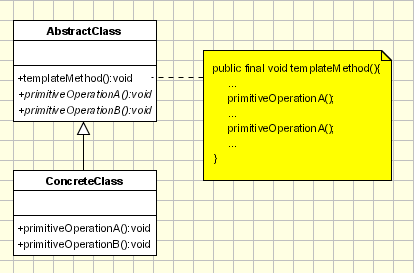
- Template method
- Visitor

Bibliografía (e imágenes tomadas de):


